Karakter Kodlama (Character Encoding)¶
Bu bölüme gelinceye kadar Python programlama dilindeki karakter dizisi, liste ve dosya adlı veri tiplerine ilişkin epey söz söyledik. Artık bu veri tiplerine dair hemen hemen bütün ayrıntıları biliyoruz. Ancak henüz öğrenmediğimiz, ama programcılık maceramız açısından mutlaka öğrenmemiz gereken çok önemli bir konu daha var. Bu önemli konunun adı, karakter kodlama.
Bu bölümde ‘karakter kodlama’ adlı hayati konuyu işlemenin yanısıra, son birkaç bölümde üstünkörü bir şekilde üzerinden geçtiğimiz, ama derinlemesine incelemeye pek fırsat bulamadığımız bütün konuları da ele almaya çalışacağız. Bu konuyu bitirdikten sonra, önceki konuları çalışırken zihninizde oluşmuş olabilecek boşlukların pek çoğunun dolduğunu farkedeceksiniz. Sözün özü, bu bölümde hem yeni şeyler söyleyeceğiz, hem de halihazırda öğrendiğimiz şeylerin bir kez daha üzerinden geçerek bunların zihnimizde iyiden iyiye pekişmesini sağlayacağız.
Hatırlarsanız önceki derslerimizde karakter dizilerinin encode() adlı bir
metodu olduğundan söz etmiştik. Aynı şekilde, dosyaların da encoding adlı bir
parametresi olduğunu söylemiştik. Ayrıca bu encoding konusu, ilk derslerimizde
metin düzenleyici ayarlarını anlatırken de karşımıza çıkmıştı. Orada, yazdığımız
programlarda özellikle Türkçe karakterlerin düzgün görünebilmesi için,
kullandığımız metin düzenleyicinin dil kodlaması (encoding) ayarlarını düzgün
yapmamız gerektiğini üstüne basa basa söylemiştik. Biz şu ana kadar bu konuyu
ayrıntılı olarak ele almamış da olsak, siz şimdiye kadar yazdığınız programlarda
Türkçe karakterleri kullanırken halihazırda pek çok problemle karşılaşmış ve bu
sorunların neden kaynaklandığını anlamakta zorlanmış olabilirsiniz.
İşte bu bölümde, o zaman henüz bilgimiz yetersiz olduğu için ertelediğimiz bu encoding konusunu bütün ayrıntılarıyla ele alacağız ve yazdığımız programlarda Türkçe karakterleri kullanırken neden sorunlarla karşılaştığımızı, bu sorunun temelinde neyin yattığını anlamaya çalışacağız.
O halde hiç vakit kaybetmeden bu önemli konuyu incelemeye başlayalım.
Giriş¶
Önceki bölümlerde sık sık tekrar ettiğimiz gibi, bilgisayar dediğimiz şey, üzerinden elektrik geçen devrelerden oluşmuş bir sistemdir. Eğer bir devrede elektrik yoksa o devrenin değeri 0 volt iken, o devreden elektrik geçtiğinde devrenin değeri yaklaşık +5 volttur.
Gördüğünüz gibi, ortada iki farklı değer var: 0 volt ve +5 volt. İkili (binary) sayma sisteminde de iki değer bulunur: 0 ve 1. İşte biz bu 0 volt’u ikili sistemde 0 ile, +5 volt’u ise 1 ile temsil ediyoruz. Yani devreden elektrik geçtiğinde o devrenin değeri 1, elektrik geçmediğinde ise 0 olmuş oluyor. Tabii bilgisayar açısından bakıldığında devrede elektrik vardır veya yoktur. Biz insanlar bu ikili durumu daha kolay bir şekilde manipüle edebilmek için farklı voltaj durumlarından her birine sırasıyla 0 ve 1 gibi bir ad veriyoruz. Yani iki farklı voltaj değerini iki farklı sayı halinde ‘kodlamış’ oluyoruz…
Hatırlarsanız bir önceki bölümde tasarladığımız basit iletişim modelinde de ampulün loş ışık vermesini sağlayan düşük elektrik sinyallerini 0 ile, parlak ışık vermesini sağlayan yüksek elektrik sinyallerini ise 1 ile temsil etmiştik. Bu temsil işine de teknik olarak ‘kodlama’ (encoding) adı verildiğini söylemiştik. İşte bilgisayarlar açısından da benzer bir durum söz konusudur. Bilgisayarlarda da 0 volt ve +5 volt değerleri sırasıyla ikili sayma sistemindeki 0 ve 1 sayıları halinde kodlanabilir.
Sözün özü ilk başta yalnızca iki farklı elektrik sinyali vardır. Elbette bu elektrik sinyalleri ile doğrudan herhangi bir işlem yapamayız. Mesela elektrik sinyallerini birbiriyle toplayıp, birbirinden çıkaramayız. Ama bu sinyalleri bir sayma sistemi ile temsil edersek (yani bu sinyalleri o sayma sisteminde kodlarsak), bunları kullanarak, örneğin, aritmetik işlemleri rahatlıkla gerçekleştirebiliriz. Mesela 0 volt ile +5 voltu birbiriyle toplayamayız, ama 0 voltu ikili sistemdeki 0 sayısıyla, +5 voltu ise ikili sistemdeki 1 sayısıyla kodladıktan sonra bu ikili sayılar arasında her türlü aritmetik işlemi gerçekleştirebiliriz.
Bilgisayarlar yalnızca iki farklı voltaj durumundan anladığı ve bu iki farklı voltaj durumu da ikili sayma sistemindeki iki farklı sayı ile kolayca temsil edilebildiği için, ilk bilgisayarlar çoğunlukla sadece hesap işlemlerinde kullanılıyordu. Karakterlerin/harflerin bilgisayar dünyasındaki işlevi bir hayli kısıtlıydı. Metin oluşturma işi o zamanlarda daktilo ve benzeri araçların görevi olarak görülüyordu. Bu durumu, telefon teknolojisi ile kıyaslayabilirsiniz. İlk telefonlar da yalnızca iki kişi arasındaki sesli iletişimi sağlamak gibi kısıtlı bir amaca hizmet ediyordu. Bugün ise, geçmişte pek çok farklı cihaza paylaştırılmış görevleri akıllı telefonlar aracılığıyla tek elden halledebiliyoruz.
Peki bir bilgisayar yalnızca elektrik sinyallerinden anlıyorsa, biz mesela bilgisayarları nasıl oluyor da metin girişi için kullanabiliyoruz?
Bu sorunun cevabı aslında çok açık: Birtakım elektrik sinyallerini, birtakım aritmetik işlemleri gerçekleştirebilmek amacıyla nasıl birtakım sayılar halinde kodlayabiliyorsak; birtakım sayıları da, birtakım metin işlemlerini gerçekleştirebilmek amacıyla birtakım karakterler halinde kodlayabiliriz.
Peki ama nasıl?
Bir önceki bölümde bahsettiğimiz basit iletişim modeli aracılığıyla bunun nasıl yapılacağını anlatmıştık. Tıpkı bizim basit iletişim sistemimizde olduğu gibi, bilgisayarlar da yalnızca elektrik sinyallerini görür. Tıpkı orada yaptığımız gibi, bilgisayarlarda da hangi elektrik sinyalinin hangi sayıya; hangi sayının da hangi karaktere karşılık geleceğini belirleyebiliriz. Daha doğrusu, bilgisayarların gördüğü bu elektrik sinyallerini sayılara ve karakterlere dönüştürebiliriz. Dışarıdan girilen karakterleri de, bilgisayarların anlayabilmesi için tam aksi istikamette sayıya, oradan da elektrik sinyallerine çevirebiliriz. İşte bu dönüştürme işlemine karakter kodlama (character encoding) adı verilir.
Bu noktada şöyle bir soru akla geliyor: Tamam, sayıları karakterlere, karakterleri de sayılara dönüştüreceğiz. Ama peki hangi sayıları hangi karakterlere, hangi karakterleri de hangi sayılara dönüştüreceğiz? Yani mesela ikili sistemdeki 0 sayısı hangi karaktere, 1 sayısı hangi karaktere, 10 sayısı hangi karaktere karşılık gelecek?
Siz aslında bu sorunun cevabını da biliyorsunuz. Yine bir önceki bölümde anlattığımız gibi, hangi sayıların hangi karakterlere karşılık geleceğini, sayılarla karakterlerin eşleştirildiği birtakım tablolalar yardımıyla rahatlıkla belirleyebiliriz.
Bu iş ilk başta kulağa çok kolaymış gibi geliyor. Esasında iş kolaydır, ama şöyle bir problem var: Herkes aynı sayıları aynı karakterlerle eşleştirmiyor olabilir. Mesela durumu bir önceki bölümde tasarladığımız basit iletişim modeli üzerinden düşünelim. Diyelim ki, başta yalnızca bir arkadaşınızla ikinizin arasındaki iletişimi sağlamak için tasarladığınız bu sistem başkalarının da dikkatini çekmiş olsun… Tıpkı sizin gibi, başkaları da loş ışık-parlak ışık karşıtlığı üzerinden birbiriyle iletişim kurmaya karar vermiş olsun. Ancak sistemin temeli herkesçe aynı şekilde kullanılıyor olsa da, karakter eşleştirme tablolarını herkes aynı şekilde kullanmıyor olabilir. Örneğin başkaları, kendi ihtiyaçları çerçevesinde, farklı sayıların farklı karakterlerle eşleştirildiği farklı tablolar tasarlamış olabilir. Bu durumun dezavantajı, farklı sistemlerle üretilen mesajların, başka sistemlerde aslı gibi görüntülenemeyecek olmasıdır. Örneğin ‘a’ harfinin 1010 gibi bir sayıyla temsil edildiği sistemle üretilen bir mesaj, aynı harfin mesela 1101 gibi bir sayıyla temsil edildiği sistemde düzgün görüntülenemeyecektir. İşte aynı şey bilgisayarlar için de geçerlidir.
1960’lı yılların ilk yarısına kadar her bilgisayar üreticisi, sayılarla karakterlerin eşleştirildiği, birbirinden çok farklı tablolar kullanıyordu. Yani her bilgisayar üreticisi farklı karakterleri farklı sayılarla eşleştiriyordu. Örneğin bir bilgisayarda 10 sayısı ‘a’ harfine karşılık geliyorsa, başka bir bilgisayarda 10 sayısı ‘b’ harfine karşılık gelebiliyordu. Bu durumun doğal sonucu olarak, iki bilgisayar arasında güvenilir bir veri aktarımı gerçekleştirmek mümkün olmuyordu. Hatta daha da vahimi, aynı firma içinde bile birden fazla karakter eşleştirme tablosunun kullanıldığı olabiliyordu…
Peki bu sorunun çözümü ne olabilir?
Cevap elbette standartlaşma.
Standartlaşma ilerleme ve uygarlık açısından çok önemli bir kavramdır. Standartlaşma olmadan ilerleme ve uygarlık düşünülemez. Eğer standartlaşma diye bir şey olmasaydı, mesela A4 piller boy ve en olarak standart bir ölçüye sahip olmasaydı, evde kullandığınız küçük aletlerin pili bittiğinde uygun pili satın almakta büyük zorluk çekerdiniz. Banyo-mutfak musluklarındaki plastik contanın belli bir standardı olmasaydı, conta eskidiğinde yenisini alabilmek için eskisinin ölçülerini inceden inceye hesaplayıp bu ölçülere göre yeni bir conta arayışına çıkmanız gerekirdi. Herhangi bir yerden bulduğunuz contayı herhangi bir muslukta kullanamazdınız. İşte bu durumun aynısı bilgisayarlar için de geçerlidir. Eğer bugün karakterlerle sayıları eşleştirme işlemi belli bir standart üzerinden yürütülüyor olmasaydı, kendi bilgisayarınızda oluşturduğunuz bir metni başka bir bilgisayarda açtığınızda aynı metni göremezdiniz. İşte 1960’lı yıllara kadar bilgisayar dünyasında da aynen buna benzer bir sorun vardı. Yani o dönemde, hangi sayıların hangi karakterlerle eşleşeceği konusunda uzlaşma olmadığı için, farklı bilgisayarlar arasında metin değiş tokuşu pek mümkün değildi.
1960’lı yılların başında IBM şirketinde çalışan Bob Bemer adlı bir bilim adamı bu kargaşanın sona ermesi gerektiğine karar verip, herkes tarafından benimsenecek ortak bir karakter kodlama sistemi üzerinde ilk çalışmaları başlattı. İşte ASCII (‘aski’ okunur) böylece hayatımıza girmiş oldu.
Peki bu ‘ASCII’ denen şey tam olarak ne anlama geliyor? Gelin bu sorunun cevabını, en baştan başlayarak ve olabildiğince ayrıntılı bir şekilde vermeye çalışalım.
ASCII¶
Bilgisayarların iki farklı elektrik sinyali ile çalıştığını, bu iki farklı sinyalin de 0 ve 1 sayıları ile temsil edildiğini, bilgisayarla metin işlemleri yapabilmek için ise bu sayıların belli karakterlerle eşleştirilmesi gerektiğini söylemiştik.
Yukarıda da bahsettiğimiz gibi, uygarlık ve ilerleme açısından standartlaşma önemli bir basamaktır. Şöyle düşünün: Biz bilgisayarların çalışma prensibinde iki farklı elektrik sinyali olduğunu biliyoruz. Biz insanlar olarak, işlerimizi daha kolay yapabilmek için, bu sinyalleri daha somut birer araç olan 0 ve 1 sayılarına atamışız. Eğer devrede elektrik yoksa bu durumu 0 ile, eğer devrede elektrik varsa bu durumu 1 ile temsil ediyoruz. Esasında bu da bir uzlaşma gerektirir. Devrede elektrik yoksa bu durumu pekala 0 yerine 1 ile de temsil edebilirdik… Eğer elektrik sinyallerinin temsili üzerinde böyle bir uzlaşmazlık olsaydı, her şeyden önce hangi sinyalin hangi sayıya karşılık geleceği konusunda da ortak bir karara varmamız gerekirdi.
Elektriğin var olmadığı durumu 0 yerine 1 ile temsil etmek akla pek yatkın olmadığı için uzlaşmada bir problem çıkmıyor. Ama karakterler böyle değildir. Onlarca (hatta yüzlerce ve binlerce) karakterin sayılarla eşleştirilmesi gereken bir durumda, ortak bir eşleştirme düzeni üzerinde uzlaşma sağlamak hiç de kolay bir iş değildir. Zaten 1960’lı yılların başına kadar da böyle bir uzlaşma sağlanabilmiş değildi. Dediğimiz gibi, her bilgisayar üreticisi sayıları farklı karakterlerle eşleştiriyor, yani birbirlerinden tamamen farklı karakter kodlama sistemleri kullanıyordu.
İşte bu kargaşayı ortadan kaldırmak gayesiyle, Bob Bemer ve ekibi hangi sayıların hangi karakterlere karşılık geleceğini belli bir standarda bağlayan bir tablo oluşturdu. Bu standarda ise American Standard Code for Information Interchange, yani ‘Bilgi Alışverişi için Standart Amerikan Kodu’ veya kısaca ‘ASCII’ adı verildi.
7 Bitlik bir Sistem¶
ASCII adı verilen sistem, birtakım sayıların birtakım karakterlerle eşleştirildiği basit bir tablodan ibarettir. Bu tabloyu https://www.asciitable.com/ adresinde görebilirsiniz:
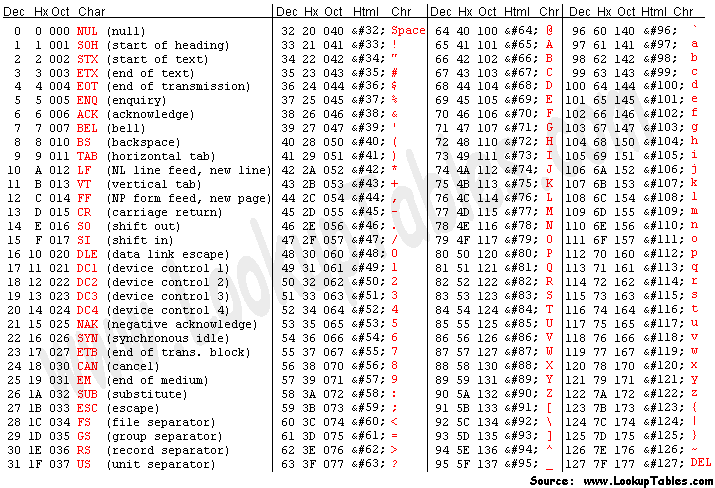
İsterseniz bu tabloyu Python yardımıyla kendiniz de oluşturabilirsiniz:
for i in range(128):
if i % 4 == 0:
print("\n")
print("{:<3}{:>8}\t".format(i, repr(chr(i))), sep="", end="")
Not
Bu kodlarda repr() fonksiyonu dışında bilmediğiniz ve
anlayamayacağınız hiçbir şey yok. Biraz sonra repr() fonksiyonundan da
bahsedeceğiz. Ama dilerseniz, bu fonksiyonun ne işe yaradığı konusunda en
azından bir fikir sahibi olmak için, yukarıdaki kodları bir de repr()
olmadan yazmayı ve aldığınız çıktıyı incelemeyi deneyebilirsiniz.
ASCII tablosunda toplam 128 karakterin sayılarla eşleştirilmiş durumda olduğunu
görüyorsunuz. Bir önceki bölümde bahsettiğimiz basit iletişim modelinde
anlattıklarımızdan da aşina olduğunuz gibi, 128 adet sayı 7 bite karşılık gelir
(2**7=128). Yani 7 bit ile gösterilebilecek son sayı 127’dir.
Dolayısıyla ASCII 7 bitlik bir sistemdir.
ASCII tablosunu şöyle bir incelediğimizde ilk 32 öğenin göze ilk başta anlamsız görünen birtakım karakterlerden oluştuğunu görüyoruz:
sayı
karakter
sayı
karakter
sayı
karakter
sayı
karakter
0
‘\x00’
1
‘\x01’
2
‘\x02’
3
‘\x03’
4
‘\x04’
5
‘\x05’
6
‘\x06’
7
‘\x07’
8
‘\x08’
9
‘\t’
10
‘\n’
11
‘\x0b’
12
‘\x0c’
13
‘\r’
14
‘\x0e’
15
‘\x0f’
16
‘\x10’
17
‘\x11’
18
‘\x12’
19
‘\x13’
20
‘\x14’
21
‘\x15’
22
‘\x16’
23
‘\x17’
24
‘\x18’
25
‘\x19’
26
‘\x1a’
27
‘\x1b’
28
‘\x1c’
29
‘\x1d’
30
‘\x1e’
31
‘\x1f’
Not
Bu arada, asciitable.com adresinden baktığınız tablo ile yukarıdaki tablonun birbirinden farklı olduğunu zannedebilirsiniz ilk bakışta. Ama aslında arada herhangi bir fark yok. Yalnızca iki tablonun karakterleri gösterim şekli birbirinden farklı. Örneğin asciitable.com’daki tabloda 9 sayısının ‘TAB (horizontal tab)’ adlı bir karaktere atandığını görüyoruz. Yukarıdaki tabloda ise 9 sayısının yanında \t adlı kaçış dizisi var. Gördüğünüz gibi, ‘TAB (horizontal tab)’ ifadesi ile \t ifadesi aynı karaktere atıfta bulunuyor. Yalnızca bunların gösterimleri birbirinden farklı, o kadar.
Aslında bu karakter salatası arasında bizim tanıdığımız birkaç karakter de yok değil. Mesela 9. sıradaki \t öğesinin sekme oluşturan kaçış dizisi olduğunu söyledik. Aynı şekilde, 10. sıradaki \n öğesinin satır başına geçiren kaçış dizisi olduğunu, 13. sıradaki \r öğesinin ise satırı başa alan kaçış dizisi olduğunu da biliyoruz. Bu tür karakterler ‘basılamayan’ (non-printing) karakterlerdir. Yani mesela ekranda görüntülenebilen ‘a’, ‘b’, ‘c’, ‘!’, ‘?’, ‘=’ gibi karakterlerden farklı olarak bu ilk 32 karakter ekranda görünmez. Bunlara aynı zamanda ‘kontrol karakterleri’ (control characters) adı da verilir. Çünkü bu karakterler ekranda görüntülenmek yerine, metnin akışını kontrol eder. Bu karakterlerin ne işe yaradığını şu tabloyla tek tek gösterebiliriz (tablo https://tr.wikipedia.org/wiki/ASCII adresinden alıntıdır):
Sayı
Karakter
Sayı
Karakter
0
boş
16
veri bağlantısından çık
1
başlık başlangıcı
17
aygıt denetimi 1
2
metin başlangıcı
18
aygıt denetimi 2
3
metin sonu
19
aygıt denetimi 3
4
aktarım sonu
20
aygıt denetimi 4
5
sorgu
21
olumsuz bildirim
6
bildirim
22
zaman uyumlu boşta kalma
7
zil
23
aktarım bloğu sonu
8
geri al
24
iptal
9
yatay sekme
25
ortam sonu
10
satır besleme/yeni satır
26
değiştir
11
dikey sekme
27
çık
12
form besleme/yeni sayfa
28
dosya ayırıcısı
13
satır başı
29
grup ayırıcısı
14
dışarı kaydır
30
kayıt ayırıcısı
15
içeri kaydır
31
birim ayırıcısı
Gördüğünüz gibi, bunlar birer harf, sayı veya noktalama işareti değil. O yüzden bu karakterler ekranda görünmez. Ama bir metindeki veri, satır ve paragraf düzeninin nasıl olacağını, metnin nerede başlayıp nerede biteceğini ve nasıl görüneceğini kontrol ettikleri için önemlidirler.
Geri kalan sayılar ise doğrudan karakterlere, sayılara ve noktalama işaretlerine tahsis edilmiştir:
sayı
karakter
sayı
karakter
sayı
karakter
sayı
karakter
32
‘ ‘
33
‘!’
34
‘”’
35
‘#’
36
‘$’
37
‘%’
38
‘&’
39
“’”
40
‘(’
41
‘)’
42
‘*’
43
‘+’
44
‘,’
45
‘-’
46
‘.’
47
‘/’
48
‘0’
49
‘1’
50
‘2’
51
‘3’
52
‘4’
53
‘5’
54
‘6’
55
‘7’
56
‘8’
57
‘9’
58
‘:’
59
‘;’
60
‘<’
61
‘=’
62
‘>’
63
‘?’
64
‘@’
65
‘A’
66
‘B’
67
‘C’
68
‘D’
69
‘E’
70
‘F’
71
‘G’
72
‘H’
73
‘I’
74
‘J’
75
‘K’
76
‘L’
77
‘M’
78
‘N’
79
‘O’
80
‘P’
81
‘Q’
82
‘R’
83
‘S’
84
‘T’
85
‘U’
86
‘V’
87
‘W’
88
‘X’
89
‘Y’
90
‘Z’
91
‘[’
92
‘\’
93
‘]’
94
‘^’
95
‘_’
96
‘’’
97
‘a’
98
‘b’
99
‘c’
100
‘d’
101
‘e’
102
‘f’
103
‘g’
104
‘h’
105
‘i’
106
‘j’
107
‘k’
108
‘l’
109
‘m’
110
‘n’
111
‘o’
112
‘p’
113
‘q’
114
‘r’
115
‘s’
116
‘t’
117
‘u’
118
‘v’
119
‘w’
120
‘x’
121
‘y’
122
‘z’
123
‘{’
124
‘|’
125
‘}’
126
‘~’
127
‘x7f’
İşte 32 ile 127 arası sayılarla eşleştirilen yukarıdaki karakterler yardımıyla metin ihtiyaçlarımızın büyük bölümünü karşılayabiliriz. Yani ASCII adı verilen bu eşleştirme tablosu sayesinde bilgisayarların sayılarla birlikte karakterleri de işleyebilmesini sağlayabiliriz.
1960’lı yıllara gelindiğinde, bilgisayarlar 8 bit uzunluğundaki verileri işleyebiliyordu. Yani, ASCII sisteminin gerçeklendiği (yani hayata geçirildiği) bilgisayarlar 8 bitlik bir kapasiteye sahipti. Bu 8 bitin 7 biti karakterle ayrılmıştı. Dolayısıyla mevcut bütün karakterler 7 bitlik bir alana sığdırılmıştı. Boşta kalan 8. bit ise, veri aktarımının düzgün gerçekleştirilip gerçekleştirilmediğini denetlemek amacıyla ‘doğruluk kontrolü’ için kullanılıyordu. Bu kontrole teknik olarak ‘eşlik denetimi’ (parity check), bu eşlik denetimini yapmamızı sağlayan bit’e ise ‘eşlik biti’ (parity bit) adı verildiğini biliyorsunuz. Geçen bölümde bu teknik terimlerin ne anlama geldiğini açıklamış, hatta bunlarla ilgili basit bir örnek de vermiştik.
Adından da anlaşılacağı gibi, ASCII bir Amerikan standardıdır. Dolayısıyla hazırlanışında İngilizce temel alınmıştır. Zaten ASCII tablosunu incelediğinizde, bu tabloda Türkçeye özgü harflerin bulunmadığını göreceksiniz. Bu sebepten, bu standart ile mesela Türkçeye özgü karakterleri gösteremeyiz. Çünkü ASCII standardında ‘ş’, ‘ç’, ‘ğ’ gibi harfler kodlanmamıştır. Özellikle Python’ın 2.x serisini kullanmış olanlar, ASCII’nin bu yetersizliğinin nelere sebep olduğunu gayet iyi bilir. Python’ın 2.x serisinde mesela doğrudan şöyle bir kod yazamayız:
print("Merhaba Şirin Baba!")
“Merhaba Şirin Baba! adlı karakter dizisinde geçen ‘Ş’ harfi ASCII dışı bir karakterdir. Yani bu harf ASCII ile temsil edilemez. O yüzden böyle bir kod yazıp bu kodu çalıştırdığımızda Python bize şöyle bir hata mesajı gösterecektir:
File "deneme.py", line 1
SyntaxError: Non-ASCII character '\xde' in file deneme.py on line 1, but no
encoding declared; see http://www.python.org/peps/pep-0263.html for details
Aynen anlattığımız gibi, yukarıdaki hata mesajı da kodlar arasında ASCII olmayan bir karakter yer aldığından yakınıyor…
ASCII’nin her ne kadar yukarıda bahsettiğimiz eksiklikleri olsa da bu standart son derece yaygındır ve piyasada bulunan pek çok sistemde kullanılmaya devam etmektedir. Örneğin size kullanıcı adı ve parola soran hemen hemen bütün sistemler bu ASCII tablosunu temel alır veya bu tablodan etkilenmiştir. O yüzden çoğu yerde kullanıcı adı ve/veya parola belirlerken Türkçe karakterleri kullanamazsınız. Hatta pek çok yazı tipinde yalnızca ASCII tablosunda yer alan karakterlerin karşılığı bulunur. Bu yüzden, mesela blogunuzda kullanmak üzere seçip beğendiğiniz çoğu yazı tipi ‘ş’, ‘ç’, ‘ğ’, ‘ö’ gibi harfleri göstermeyebilir. Yukarıda ‘Merhaba Şirin Baba!’ örneğinde de gösterdiğimiz gibi, Python’ın 2.x serisinde de öntanımlı olarak ASCII kodlama biçimi kullanılıyordu. O yüzden Python’ın 2.x sürümlerinde Türkçe karakterleri gösterebilmek için daha fazla ilave işlem yapmak zorunda kalıyorduk.
Sözün özü, eğer yazdığınız veya kendiniz yazmamış da olsanız herhangi bir sebeple kullanmakta olduğunuz bir programda Türkçe karakterlere ilişkin bir hata alıyorsanız, bu durumun en muhtemel sebebi, kullandığınız programın veya sistemin, doğrudan ASCII’yi veya ASCII’ye benzer başka bir sistemi temel alarak çalışıyor olmasıdır. ASCII tablosunda görünen 128 karakter dışında kalan hiçbir karakter ASCII ile kodlanamayacağı için, özellikle farklı dillerin kullanıldığı bilgisayarlarda çalışan programlar kaçınılmaz olarak karakterlere ilişkin pek çok hata verecektir. Örneğin, karakter kodlamalarına ilişkin olarak yukarıda bahsettiğimiz ayrıntılardan habersiz bir Amerikalı programcının yazdığı bir programa Türkçe veri girdiğinizde bu program bir anda tuhaf görünen hatalar verip çökecektir…
Genişletilmiş ASCII¶
Dediğimiz gibi, ASCII 7 bitlik bir karakter kümesidir. Bu standardın ilk çıktığı dönemde 8. bitin hata kontrolü için kullanıldığını söylemiştik. Sonraki yıllarda 8. bitin hata kontrolü için kullanılmasından vazgeçildi. Böylece 8. bit yine boşa düşmüş oldu. Bu bitin boşa düşmesi ile elimizde yine toplam 128 karakterlik bir boşluk olmuş oldu. Dediğimiz gibi 7 bit ile toplam 128 sayı-karakter eşleştirilebilirken, 8 bit ile toplam 256 sayı-karakter eşleştirilebilir. Ne de olsa:
>>> 2**7
128
>>> 2**8
256
İşte bu fazla bit, farklı kişi, kurum ve organizasyonlar tarafından, İngilizcede bulunmayan ama başka dillerde bulunan karakterleri temsil etmek için kullanıldı. Ancak elbette bu fazladan bitin sağladığı 128 karakter de dünyadaki bütün karakterlerin temsil edilmesine yetmez. Bu yüzden 8. bitin sunduğu boşluk, birbirinden farklı karakterleri gösteren çeşitli tabloların ortaya çıkmasına sebep oldu. Bu birbirinden farklı tablolara genel olarak ‘kod sayfası’ adı verilir. Örneğin Microsoft şirketinin Türkiye’ye gönderdiği bilgisayarlarda tanımlı ‘cp857’ adlı kod sayfasında 128 ile 256 aralığında Türkçe karakterlere de yer verilmişti (bkz).
Bu tabloya baktığınızda baştan 128’e kadar olan karakterlerin standart ASCII tablosu ile aynı olduğunu göreceksiniz. 128. karakterden itibaren ise Türkçeye özgü harfler tanımlanır. Mesela bu tabloda 128. karakter Türkçedeki büyük ‘ç’ harfi iken, 159. karakter küçük ‘ş’ harfidir. Bu durumu şu Python kodları ile de teyit edebilirsiniz:
>>> "Ç".encode("cp857")
b'\x80'
>>> "ş".encode("cp857")
b'\x9f'
Bu arada bu sayıların onaltılı sayma düzenine göre olduğunu biliyorsunuz. Onlu düzende bunların karşılığı sırasıyla şudur:
>>> int("80", 16)
128
>>> int("9f", 16)
159
Burada karakter dizilerinin encode() adlı metodunu kullandığımıza dikkat
edin. Bu metot yardımıyla herhangi bir karakteri herhangi bir karakter kodlama
sistemine göre kodlayabiliriz. Mesela yukarıdaki iki örnekte ‘Ç’ ve ‘ş’
harflerini ‘cp857’ adlı kod sayfasına göre kodladık ve bunların bu kod
sayfasında hangi sayılara karşılık geldiğini bulduk.
cp857 numaralı kod sayfasında ‘Ç’ ve ‘ş’ harfleri yer aldığı için, biz bu harfleri o kod sayfasına göre kodlayabiliyoruz. Ama mesela ASCII kodlama sisteminde bu harfler bulunmaz. O yüzden bu harfleri ASCII sistemine göre kodlayamayız:
>>> "Ç".encode("ascii")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\xc7' in position
0: ordinal not in range(128)
Tıpkı hata mesajında da söylendiği gibi:
Unicode Kodlama Hatası: 'ascii' kod çözücüsü, 0 konumundaki '\xc7' adlı
karakteri kodlayamıyor. Sayı 0-128 aralığında değil.
Gerçekten de onlu sistemde 199 sayısına karşılık gelen bu onaltılı ‘\xc7’ sayısı ASCII’nin kapsadığı sayı aralığının dışında kalmakta, bu yüzden de ASCII kod çözücüsü ile kodlanamamaktadır.
Dediğimiz gibi, Microsoft Türkiye’ye gönderdiği bilgisayarlarda 857 numaralı kod sayfasını tanımlıyordu. Ama mesela Arapça konuşulan ülkelere gönderdiği bilgisayarlarda ise, bu adresten görebileceğiniz 708 numaralı kod sayfasını tanımlıyordu. Bu kod sayfasını incelediğinizde, 128 altı karakterlerin standart ASCII ile aynı olduğunu ancak 128 üstü karakterlerin Türkçe kod sayfasındaki karakterlerden farklı olduğunu göreceksiniz. İşte 128 üstü karakterler bütün dillerde birbirinden farklıdır. Bu farklılığın ne sonuç doğurabileceğini tahmin edebildiğinizi zannediyorum. Elbette, mesela kendi bilgisayarınızda yazdığınız bir metni Arapça konuşulan bir ülkedeki bilgisayara gönderdiğinizde, doğal olarak metin içindeki Türkçeye özgü karakterlerin yerinde başka karakterler belirecektir.
Bu bölümün başında da söylediğimiz gibi, Genişletilmiş ASCII sisteminde 128 ile 256 aralığı için pek çok farklı karakter eşleştirme tabloları kullanılıyordu. Mesela Microsoft şirketi bu aralık için kendine özgü birtakım kod sayfaları tasarlamıştı. Bu kod sayfalarına örnek olarak yukarıda cp857 ve cp708 numaralı kod sayfalarını örnek vermiştik.
Elbette 128 ile 256 aralığını dolduran, yalnızca Microsoft’a ait kod sayfaları yoktu piyasada. Aynı aralığı farklı karakterlerle dolduran pek çok başka eşleştirme tablosu da dolaşıyordu etrafta. Örneğin özellikle Batı Avrupa dillerindeki karakterleri temsil edebilmek için oluşturulmuş ‘latin1’ (öbür adıyla ISO-8859-1) adlı karakter kümesi bugün de yaygın olarak kullanılan sistemlerinden biridir. Almancada olup da ASCII sistemi ile temsil edilemeyen ‘ö’, ‘ß’, ‘ü’ gibi harfler ve Fransızcada olup da yine ASCII sistemi ile temsil edilemeyen ‘ç’ ve ‘é’ gibi harfler bu karakter kümesinde temsil edilebiliyordu. Eğer dilerseniz bu karakter kümesini de https://www.fileformat.info/info/charset/ISO-8859-1/list.htm adresinden inceleyebilirsiniz.
Yalnız burada önemli bir ayrıntıyı not düşelim. ‘Genişletilmiş ASCII’, standart ASCII gibi genel kabul görmüş tek bir sistem değildir.Genişletilmiş ASCII dediğimizde zaten tek bir karakter kümesi akla gelmiyor. Dolayısıyla ASCII dendiğinde anlamamız gereken şey 128 karakterlik bir sayı-karakter eşleştirme tablosudur. ASCII hiçbir zaman bu 128 karakterin ötesine geçip de 256 karakterlik bir aralığı temsil etmiş değildir. Dolayısıyla 127. sayının ötesindeki karakterleri kapsayan sistem ASCII değildir. ‘Genişletilmiş ASCII’ kavramı, temel ASCII sisteminde temsil edilen sayı-karakter çiftlerinin pek çok farklı kurum ve kuruluş tarafından birbirinden farklı biçimlerde ‘genişletilmesiyle’ oluşturulmuş, ancak ASCII’nin kendisi kadar standartlaşamamış bir sistemler bütünüdür. Bu sistem içinde pek çok farklı kod sayfası (veya karakter kümesi) yer alır. Tek başına ‘Genişletilmiş ASCII’ ifadesi açıklayıcı olmayıp; ASCII’nin hangi karakter kümesine göre genişletildiğinin de belirtilmesi gerekir.
Bütün bu anlattıklarımızdan şu sonucu çıkarıyoruz: ASCII bilgisayarlar arasında güvenli bir şekilde veri aktarımını sağlamak için atılmış en önemli ve en başarılı adımlardan bir tanesidir. Bu güçlü standart sayesinde uzun yıllar bilgisayarlar arası temel iletişim başarıyla sağlandı. Ancak bu standardın zayıf kaldığı nokta 7 bitlik olması ve boşta kalan 8. bitin tek başına dünyadaki bütün dilleri temsil etmeye yeterli olmamasıdır.
1 Karakter == 1 Bayt¶
ASCII standardı, her karakterin 1 bayt ile temsil edilebileceği varsayımı üzerine kurulmuştur. Bildiğiniz gibi, 1 bayt (geleneksel olarak) 8 bit’e karşılık gelir. Peki 1 bayt’ın 8 bit’e karşılık gelmesinin nedeni nedir? Aslında bunun özel bir nedeni yok. 1 destede neden 10 öğe, 1 düzinede de 12 öğe varsa, 1 bayt’ta da 8 bit vardır… Yani biz insanlar öyle olmasına karar verdiğimiz için 1 destede 10 öğe, 1 düzinede 12 öğe, 1 bayt’ta ise 8 bit vardır.
Dediğimiz gibi ASCII standardı 7 bitlik bir sistemdir. Yani bu standartta en büyük sayı olan 127 yalnızca 7 bit ile gösterilebilir:
>>> bin(127)[2:]
'1111111'
127 sayısı 7 bit ile gösterilebilecek son sayıdır:
>>> (127).bit_length()
7
>>> (128).bit_length()
8
8 bitlik bir sistem olan Genişletilmiş ASCII ise 0 ile 255 arası sayıları temsil edebilir:
>>> bin(255)[2:]
'11111111'
255 sayısı 8 bit ile gösterilebilecek son sayıdır:
>>> (255).bit_length()
8
>>> (256).bit_length()
9
Dolayısıyla ASCII’de ve Genişletilmiş ASCII’de 1 baytlık alana toplam 256 karakter sığdırılabilir. Eğer daha fazla karakteri temsil etmek isterseniz 1 bayttan fazla bir alana ihtiyaç duyarsınız.
Bu arada, olası bir yanlış anlamayı önleyelim:
1 bayt olma durumu mesela doğrudan ‘a’ harfinin kendisi ile ilgili bir şey değildir. Yani ‘a’ harfi 1 bayt ile gösterilebiliyorken, mesela ‘ş’ harfi 1 bayt ile gösterilemiyorsa, bunun nedeni ‘ş’ harfininin ‘tuhaf bir harf’ olması değildir! Eğer ASCII gibi bir sistem Türkiye’de tasarlanmış olsaydı, herhalde ‘ş’ harfi ilk 128 sayı arasında kendine bir yer bulurdu. Mesela böyle bir sistemde muhtemelen ‘x’, ‘w’ ve ‘q’ harfleri, Türk alfabesinde yer almadıkları için, dışarıda kalırdı. O zaman da ‘ş’, ‘ç’, ‘ğ’ gibi harflerin 1 bayt olduğunu, ‘x’, ‘w’ ve ‘q’ gibi harflerin ise 1 bayt olmadığını söylerdik.
UNICODE¶
İlk bilgisayarların ABD çıkışlı olması nedeniyle, bilgisayarlar çoğunlukla ABD’de üretilip ABD pazarına satılıyordu. Bu nedenle İngilizce alfabeyi temel alan ASCII gibi bir sistem bu pazarın karakter temsil ihtiyaçlarını %99 oranında karşılıyordu. Ancak bilgisayarların ABD dışına çıkması ve ABD dışında da da yayılmaya başlamasının ardından, ASCII’nin yetersizlikleri de iyice görünür olmaya başladı. Çünkü ASCII tablosunda, İngilizce dışındaki dillerde bulunan aksanlı ve noktalı harflerin (é, ä, ö, ç gibi) hiçbiri bulunmuyordu.
İlk zamanlarda insanlar aksanlı ve noktalı harfleri ASCII tablosundaki benzerleriyle değiştirerek kullanmaya razı olmuşlardı (é yerine e; ä yerine a; ö yerine o; ç yerine c gibi). Ancak bu çözüm Avrupa dillerini kullananların sorununu kısmen çözüyor da olsa, Asya dillerindeki problemi çözemez. Çünkü ASCII tablosunu kullanarak Çince ve Japonca gibi dillerdeki karakterleri herhangi bir şekilde temsil etmeniz mümkün değildir.
Bu sıkıntıyı kısmen de olsa giderebilmek için, yukarıda da bahsetmiş olduğumuz, 128-256 arasındaki boşluktan yararlanılmaya başlandı. Dediğimiz gibi, ASCII 7 bitlik bir sistem olduğu için, 8 bitlik bilgisayarlarda fazladan 1 bitin boşta kalmasına izin verir. İşte bu 1 bitlik boşluk dünyanın çeşitli ülkeleri tarafından kendi karakter ihtiyaçlarını karşılamak için kullanıldı. Dolayısıyla Almanlar 128-256 arasını farklı karakterlerle, Fransızlar başka karakterlerle, Yunanlar ise bambaşka karakterlerle doldurdular.
Hatırlarsanız ASCII’nin ortaya çıkış sebebi bilgisayarlar arasında veri alışverişini mümkün kılmaktı. ASCII Amerika’daki bilgisayarlar arasında sağlıklı bir veri alışverişi gerçekleştirilmesini rahatlıkla mümkün kılıyordu. Ama bilgisayarların dünyaya yayılması ile birlikte ilk baştaki veri aktarımı problemi tekrar ortaya çıktı. Bu defa da, mesela Türkiye’den gönderilen bir metin (örneğin bir e.posta) Almanya’daki bilgisayarlarda düzgün görüntülenemeyebiliyordu. Örneğin Windows-1254 (cp1254) numaralı kod sayfası ile kodlanmış Türkçe bir metin, Almanya’da Windows-1250 numaralı kod sayfasının tanımlı olduğu bir bilgisayarda, aynı sayıların her iki kod sayfasında farklı karakterlere karşılık gelmesi nedeniyle düzgün görüntülenemez.
Not
Windows-1254 adlı kod sayfası için https://en.wikipedia.org/wiki/Windows-1254 adresine; Windows-1250 adlı kod sayfası için ise https://en.wikipedia.org/wiki/Windows-1250 adresine bakabilirsiniz.
İşte nasıl 1960’lı yılların başında Bob Bemer ve arkadaşları bilgisayarlar arasında sağlıklı bir veri iletişimi sağlamak için kolları sıvayıp ASCII gibi bir çözüm ürettiyse, ASCII ve Genişletilmiş ASCII ile kodlanamayan karakterleri de kodlayıp, uluslar arasında çok geniş çaplı veri alışverişine izin verebilmek amacıyla Xerox şirketinden Joe Becker, Apple şirketinden ise Lee Collins ve Mark Davis UNICODE adlı bir çözüm üzerinde ilk çalışmaları başlattı.
Peki tam olarak nedir bu UNICODE denen şey?
Aslında Unicode da tıpkı ASCII gibi bir standarttır. Unicode’un bir proje olarak ortaya çıkışı 1987 yılına dayanır. Projenin amacı, dünyadaki bütün dillerde yer alan karakterlerin tek, benzersiz ve doğru bir biçimde temsil edilebilmesidir. Yani bu projenin ortaya çıkış gayesi, ASCII’nin yetersiz kaldığı noktaları telafi etmektir.
Sınırsız Bitlik bir Sistem¶
Unicode standardı ile ilgili olarak bilmemiz gereken ilk şey bu standardın ASCII’yi tamamen görmezden gelmiyor olmasıdır. Daha önce de söylediğimiz gibi, ASCII son derece yaygın ve güçlü bir standarttır. Üstelik ASCII standardı yaygın olarak kullanılmaya da devam etmektedir. Bu sebeple ASCII ile halihazırda kodlanmış karakterler UNICODE standardında da aynı şekilde kodlanmıştır. Dolayısıyla ASCII UNICODE sisteminin bir alt kümesi olduğu için, ASCII ile uyumlu olan bütün sistemler otomatik olarak UNICODE ile de uyumludur. Ancak tabii bunun tersi geçerli değildir.
UNICODE’un ASCII’den en önemli farkı, UNICODE’un ASCII’ye kıyasla çok daha büyük miktarda karakterin kodlanmasına izin vermesidir. ASCII yalnızca 128 karakterin kodlanmasına izin verirken UNICODE 1.000.000’dan fazla karakterin kodlanmasına izin verir.
UNICODE sistemini devasa bir karakter tablosu olarak hayal edebilirsiniz.
Bildiğiniz gibi ASCII 7 bitlik bir sistemdir. Bu sebeple de sadece 128 karakteri
kodlayabilir. UNICODE ilk ortaya çıktığında 16 bitlik bir sistem olarak
tasarlanmıştı. Dolayısıyla UNICODE daha ilk çıkışında 2**16=65536 karakterin
kodlanmasına izin veriyordu. Bugün ise UNICODE sisteminin böyle kesin bir sınırı
yoktur. Çünkü ‘bilmem kaç bitlik bir sistem’ kavramı UNICODE için geçerli
değildir. Dediğimiz gibi, UNICODE’u, ucu bucağı olmayan dev bir karakter tablosu
olarak düşünebilirsiniz. Bu tabloya istediğimiz kadar karakteri ekleyebiliriz.
Bizi engelleyen sınırlı bir bit kavramı mevcut değildir. Çünkü UNICODE
sisteminin kendisi, ASCII sisteminin aksine, doğrudan doğruya karakterleri
kodlamaz. UNICODE’un yaptığı şey karakterleri tanımlamaktan ibarettir.
Unicode sisteminde her karakter tek ve benzersiz bir ‘kod konumuna’ (code point) karşılık gelir. Kod konumları şu formüle göre gösterilir:
U+sayının_onaltılı_değeri
Örneğin ‘a’ harfinin kod konumu şudur:
u+0061
Buradaki 0061 sayısı onaltılı bir sayıdır. Bunu onlu sayı sistemine çevirebilirsiniz:
>>> int("61", 16)
97
Hatırlarsanız ‘a’ harfinin ASCII tablosundaki karşılığı da 97 idi.
Esasında ASCII ile UNICODE birbirleri ile karşılaştırılamayacak iki farklı kavramdır. Neticede ASCII bir kodlama biçimidir. UNICODE ise pek çok farklı kodlama biçimini içinde barındıran devasa bir sistemdir.
Not
Unicode standardına http://www.unicode.org/versions/Unicode6.2.0/UnicodeStandard-6.2.pdf adresinden ulaşabilirsiniz.
UTF-8 Kod Çözücüsü¶
Dediğimiz gibi UNICODE devasa bir tablodan ibarettir. Bu tabloda karakterlere ilişkin birtakım bilgiler bulunur ve bu sistemde her karakter, kod konumları ile ifade edilir. UNICODE kendi başına karakterleri kodlamaz. Bu sistemde tanımlanan karakterleri kodlama işi kod çözücülerin görevidir.
UNICODE sistemi içinde UTF-1, UTF-7, UTF-8, UTF-16 ve UTF-32 adlı kod çözücüler bulunur. UTF-8, UNICODE sistemi içindeki en yaygın, en bilinen ve en kullanışlı kod çözücüdür.
UTF-8 adlı kod çözücünün kodlayabildiği karakterlerin listesine https://www.fileformat.info/info/charset/UTF-8/list.htm adresinden ulaşabilirsiniz. Bu listenin sayfalar dolusu olduğuna ve her sayfaya, sayfanın en altındaki ‘More…’ bağlantısı ile ulaşabileceğinize dikkat edin.
1 Karakter != 1 Bayt¶
ASCII sisteminde her karakterin 1 bayt’a karşılık geldiğini söylemiştik. Ancak 1 bayt dünyadaki bütün karakterleri kodlamaya yetmez. Geri kalan karakterleri de kodlayabilmek için 1 bayttan fazlasına ihtiyacımız var. Mesela karakter kodlama için:
1 bayt kullanırsak toplam 2**8 = 256
2 bayt kullanırsak toplam 2**16 = 65,536
3 bayt kullanırsak toplam 2**24 = 16,777,216
4 bayt kullanırsak toplam 2**32 = 4,294,967,296
karakter kodlayabiliriz. Bu durumu şu Python kodları ile de gösterebiliriz:
>>> for i in range(1, 5):
... print("{} bayt kullanırsak toplam 2**{:<2} = {:,}".format(i, i*8, (2**(i*8))))
Görünüşe göre biz 4 baytlık bir sistem kullanırsak gelmiş geçmiş bütün karakterleri rahatlıkla temsil etmeye yetecek kadar alana sahip oluyoruz. Ancak burada şöyle bir durum var. Bildiğiniz gibi, 0 ile 256 aralığındaki karakterler yalnızca 1 bayt ile temsil edilebiliyor. 256 ile 65,536 arasındaki karakterler için ise 2 bayt yeter. Aynı şekilde 65,536 ile 16,777,216 aralığındaki sayılar için de 3 bayt yeterli. Bu durumda eğer biz bütün karakterleri 4 bayt ile temsil edecek olursak, korkunç derece bir israfa düşmüş oluruz. Çünkü ASCII gibi bir kodlama sisteminde yalnızca 1 bayt ile temsil edilebilecek bir karakterin kapladığı alan bu sistemle boşu boşuna 4 kat artmış olacaktır.
Bu sorunun çözümü elbette sabit boyutlu karakter kodlama biçimleri yerine değişken boyutlu karakter kodlama biçimleri kullanmaktır. İşte UNICODE sistemi içindeki UTF-8 adlı kod çözücü, karakterleri değişken sayıda baytlar halinde kodlayabilir. UTF-8, UNICODE sistemi içinde tanımlanmış karakterleri kodlayabilmek için 1 ile 4 bayt arası değerleri kullanır. Böylece de bu kod çözücü UNICODE sistemi içinde tanımlanmış bütün karakterleri temsil edebilir.
Bu durumu bir örnek üzerinden göstermeye çalışalım:
harfler = "abcçdefgğhıijklmnoöprsştuüvyz"
for s in harfler:
print("{:<5}{:<15}{:<15}".format(s,
str(s.encode("utf-8")),
len(s.encode("utf-8"))))
Buradan şuna benzer bir çıktı alıyoruz:
a b'a' 1
b b'b' 1
c b'c' 1
ç b'\xc3\xa7' 2
d b'd' 1
e b'e' 1
f b'f' 1
g b'g' 1
ğ b'\xc4\x9f' 2
h b'h' 1
ı b'\xc4\xb1' 2
i b'i' 1
j b'j' 1
k b'k' 1
l b'l' 1
m b'm' 1
n b'n' 1
o b'o' 1
ö b'\xc3\xb6' 2
p b'p' 1
r b'r' 1
s b's' 1
ş b'\xc5\x9f' 2
t b't' 1
u b'u' 1
ü b'\xc3\xbc' 2
v b'v' 1
y b'y' 1
z b'z' 1
Burada, s.encode("utf-8") komutunun ‘baytlar’ (bytes) türünden bir veri
tipi verdiğine dikkat edin (baytlar veri tipini bir sonraki bölümde ayrıntılı
olarak inceleyeceğiz). Karakter dizilerinin aksine baytların format() adlı
bir metodu bulunmaz. Bu yüzden, bu veri tipini format() metoduna göndermeden
önce str() fonksiyonu yardımıyla karakter dizisine dönüştürmemiz gerekiyor.
Bu dönüştürme işlevini, alternatif olarak şu şekilde de yapabilirdik:
print("{:<5}{!s:<15}{:<15}".format(s,
s.encode("utf-8"),
len(s.encode("utf-8"))))
Hangi yöntemi seçeceğiniz paşa gönlünüze kalmış… Biz konumuza dönelim.
Yukarıdaki tabloda ilk sütun Türk alfabesindeki tek tek harfleri gösteriyor. İkinci sütun ise bu harflerin UTF-8 ile kodlandığında nasıl göründüğünü. Son sütunda ise UTF-8 ile kodlanan Türk harflerinin kaç baytlık yer kapladığını görüyoruz.
Bu tabloyu daha iyi anlayabilmek için mesela buradaki ‘ç’ harfini ele alalım:
>>> 'ç'.encode('utf-8')
b'\xc3\xa7'
Burada Python’ın kendi yerleştirdiği karakterleri çıkarırsak (‘b’ ve ‘\x’ gibi) elimizde şu onaltılı sayı kalır:
c3a7
Bu onaltılı sayının onlu sistemdeki karşılığı şudur:
>>> int('c3a7', 16)
50087
50087 sayısının ikili sayma sistemindeki karşılığı ise şudur:
>>> bin(50087)
'0b1100001110100111'
Gördüğünüz gibi, bu sayı 16 bitlik, yani 2 baytlık bir sayıdır. Bunu nasıl teyit edeceğinizi biliyorsunuz:
>>> (50087).bit_length()
16
https://www.fileformat.info/info/charset/UTF-8/list.htm adresine gittiğinizde de UTF-8 tablosunda ‘ç’ harfinin ‘c3a7’ sayısıyla eşleştirildiğini göreceksiniz.
Bir de UTF-8’in ‘a’ harfini nasıl temsil ettiğine bakalım:
>>> "a".encode("utf-8")
b'a'
‘a’ harfi standart ASCII harflerinden biri olduğu için Python doğrudan bu harfin kendisini gösteriyor. Eğer bu harfin hangi sayıya karşılık geldiğini görmek isterseniz şu kodu kullanabilirsiniz:
>>> ord("a")
97
Daha önce de söylediğimiz gibi, UNICODE sistemi ASCII ile uyumludur. Yani ASCII sisteminde tanımlanmış bir harf hangi sayı değerine sahipse, UNICODE içindeki bütün kod çözücüleri de o harf için aynı sayıyı kullanır. Yani mesela ‘a’ harfi hem ASCII’de, hem UTF-8’de 97 sayısı ile temsil edilir. Bu sayı 256’dan küçük olduğu için yalnızca 1 bayt ile temsil edilir. Ancak standart ASCII dışında kalan karakterler, farklı kod çözücüler tarafından farklı sayılarla eşleştirilecektir. Bununla ilgili şöyle bir çalışma yapabiliriz:
kod_çözücüler = ['UTF-8', 'cp1254', 'latin-1', 'ASCII']
harf = 'İ'
for kç in kod_çözücüler:
try:
print("'{}' karakteri {} ile {} olarak "
"ve {} sayısıyla temsil edilir.".format(harf, kç,
harf.encode(kç),
ord(harf)))
except UnicodeEncodeError:
print("'{}' karakteri {} ile temsil edilemez!".format(harf, kç))
Bu programı çalıştırdığımızda şuna benzer bir çıktı alırız:
.. code-block:: pycon
‘İ’ karakteri UTF-8 ile b’xc4xb0’ olarak ve 304 sayısıyla temsil edilir ‘İ’ karakteri cp1254 ile b’xdd’ olarak ve 304 sayısıyla temsil edilir. ‘İ’ karakteri latin-1 ile temsil edilemez! ‘İ’ karakteri ASCII ile temsil edilemez!
Bu ufak programı kullanarak hangi karakterin hangi kod çözücü ile nasıl temsil edildiğini (veya temsil edilip edilemediğini) görebilirsiniz.
Eksik Karakterler ve encode Metodu¶
Dediğimiz ve örneklerden de gördüğümüz gibi, her karakter her kod çözücü ile çözülemeyebilir. Mesela Windows-1254 adlı kod sayfasında bulunan bir karakter Windows-1250 adlı kod sayfasında bulunamadığında, bulunmayan karakterin yerine bir soru işareti (veya başka bir simge) yerleştirilecektir.
Aslında siz bu olguya hiç yabancı değilsiniz. İnternette dolaşırken mutlaka anlamsız karakterlerle dolu web sayfalarıyla karşılaşmışsınızdır. Bu durumun sebebi, ilgili sayfanın dil kodlamasının (encoding) düzgün belirtilmemiş olmasıdır. Yani sayfanın HTML kodları arasında meta charset etiketi ya hiç yazılmamış ya da yanlış yazılmıştır. Eğer bu etiket hiç yazılmamışsa, Internet tarayıcınız dil kodlamasının ne olduğunu kendince tahmin etmeyece çalışacak, çoğunlukla da yanlış bir karar verecektir. Tarayıcınız metnin dilini düzgün tespit edemediği için de bu metni yanlış bir karakter tablosu ile eşleştirecek, o karakter tablosunda tanımlanmamış karakterler yerine bir soru işareti veya başka anlamsız bir simge yerleştirecektir. Metni düzgün görüntüleyebilmek için tarayıcınızın dil kodlamasının yapıldığı menü öğesini bulup, doğru dil kodlamasını kendiniz seçeceksiniz. Böyle bir şeyi hayatınız boyunca en az bir kez yapmak zorunda kaldığınıza eminim…
Bir karakter kümesinde herhangi bir karakter bulunamadığında, bulunamayan bu karakterin yerine neyin geleceği, tamamen aradaki yazılıma bağlıdır. Örneğin söz konusu olan bir Python programıysa, ilgili karakter bulunamadığında öntanımlı olarak bu karakterin yerine hiçbir şey koyulmaz. Onun yerine program çökmeye bırakılır… Ancak böyle bir durumda ne yapılacağını isterseniz kendiniz de belirleyebilirsiniz.
Bunun için karakter dizilerinin encode() metodunun errors adlı
parametresinden yararlanacağız. Bu parametre dört farklı değer alabilir:
Parametre
Anlamı
‘strict’
Karakter temsil edilemiyorsa hata verilir
‘ignore’
Temsil edilemeyen karakter görmezden gelinir
‘replace’
Temsil edilemeyen karakterin yerine bir ‘?’ işareti koyulur
‘xmlcharrefreplace’
Temsil edilemeyen karakter yerine XML karşılığı koyulur
Bu parametreleri şöyle kullanıyoruz:
>>> "bu Türkçe bir cümledir.".encode("ascii", errors="strict")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\xfc' in
position 4: ordinal not in range(128)
‘strict’ zaten öntanımlı değerdir. Dolayısıyla eğer errors parametresine herhangi bir değer vermezsek Python sanki ‘strict’ değerini vermişiz gibi davranacak ve ilgili karakter kodlaması ile temsil edilemeyen bir karakter ile karşılaşıldığında hata verecektir:
>>> "bu Türkçe bir cümledir.".encode("ascii")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\xfc' in
position 4: ordinal not in range(128)
Gelelim öteki değerlerin ne yaptığına:
>>> "bu Türkçe bir cümledir.".encode("ascii", errors="ignore")
b'bu Trke bir cmledir.'
Gördüğünüz gibi, errors parametresine ‘ignore’ değerini verdiğimizde, temsil edilemeyen karakterler görmezden geliniyor:
>>> "bu Türkçe bir cümledir.".encode("ascii", errors="replace")
b'bu T?rk?e bir c?mledir.'
Burada ise ‘replace’ değerini kullandık. Böylece temsil edilemeyen karakterlerin yerine birer ? işareti koyuldu:
>>> "bu Türkçe bir cümledir.".encode("ascii", errors="xmlcharrefreplace")
b'bu Türkçe bir cümledir.'
Son olarak ise ‘xmlcharrefreplace’ değerinin ne yaptığını görüyoruz. Eğer errors parametresine ‘xmlcharrefreplace’ değerini verecek olursak, temsil edilemeyen her bir harf yerine o harfin XML karşılığı yerleştirilir. Bu değer, programınızdan alacağınız çıktıyı bir XML dosyasında kullanacağınız durumlarda işinize yarayabilir.
Dosyalar ve Karakter Kodlama¶
Dosyalar konusunu anlatırken, Python’da bir dosyanın open() fonksiyonu ile
açılacağını söylemiştik. Bildiğiniz gibi open() fonksiyonunu şu şekilde
kullanıyoruz:
>>> f = open(dosya_adı, dosya_açma_kipi)
Burada biz open() fonksiyonunu iki farklı parametre ile birlikte kullandık.
Ancak aslında belirtmemiz gereken önemli bir parametresi daha var bu
fonksiyonun. İşte bu parametrenin adı encoding’dir.
Gelin şimdi bu parametrenin ne olduğuna ve nasıl kullanıldığına bakalım:
encoding¶
Tahmin edebileceğiniz gibi, encoding parametresi bir dosyanın hangi kod çözücü
ile açılacağını belirtmemizi sağlar. Python’da dosyalar öntanımlı olarak
locale adlı bir modülün getpreferredencoding() adlı fonksiyonunun
gösterdiği kod çözücü ile açılır. Siz de dosyalarınızın varsayılan olarak hangi
kod çözücü ile açılacağını öğrenmek için şu komutları yazabilirsiniz:
>>> import locale
>>> locale.getpreferredencoding()
İşte eğer siz encoding parametresini belirtmezseniz, dosyalarınız yukarıdaki çıktıda görünen kod çözücü ile açılacaktır.
GNU/Linux dağıtımlarında bu çıktı çoğunlukla UTF-8 olacaktır. O yüzden
GNU/Linux’ta dosyalarınız muhtemelen encoding belirtmeseniz bile düzgün
görünecektir. Ancak Windows’ta locale.getpreferredencoding() değeri cp1254
olacağı için, mesela UTF-8 ile kodlanmış dosyalarınızda özellikle Türkçe
karakterler düzgün görüntülenemeyecektir. O yüzden, dosyalarınızın hangi kod
çözücü ile kodlanmış olduğunu open() fonksiyonuna vereceğiniz encoding
parametresi aracılığıyla her zaman belirtmelisiniz:
>>> f = open(dosya, encoding='utf-8')
Diyelim ki açmak istediğiniz dosya cp1254 adlı kod çözücü ile kodlanmış olsun. Eğer siz bu dosyayı açarken cp1254 adlı kod çözücüyü değil de başka bir kod çözücüyü yazarsanız elbette dosyadaki karakterler düzgün görüntülenemeyecektir.
Örneğin cp1254 ile kodlanmış bir belgeyi UTF-8 ile açmaya kalkışırsanız veya siz hiçbir kod çözücü belirtmediğiniz halde kullandığınız işletim sistemi öntanımlı olarak dosyaları açmak için cp1254 harici bir kod çözücüyü kullanıyorsa, dosyayı okuma esnasında şuna benzer bir hata alırsınız:
>>> f = open("belge.txt", encoding="utf-8")
>>> f.read(50)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python33\lib\codecs.py", line 300, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xde in position 79: invalid
continuation byte
Gördüğünüz gibi, dosyamız bizim kullanmaya çalıştığımız kod çözücüden (UTF-8) farklı bir kod çözücü ile (cp1254) kodlanmış olduğu için, doğal olarak karakterler doğru sayılarla eşleştirilemiyor. Bu da kaçınılmaz olarak yukarıdaki hatanın verilmesine sebep oluyor.
Aslında siz bu hatayı tanıyorsunuz. encode() metodunu anlatırken bunun ne
olduğundan ve bu hataya karşı neler yapabileceğinizden söz etmiştik.
Hatırlarsanız bu tür hatalara karşı ne tepki verileceğini belirleyebilmek için
encode() metodunda errors adlı bir parametreyi kullanabiliyorduk. İşte
open() fonksiyonunda da aynı errors parametresi bulunur.
errors¶
Dediğimiz gibi, bir dosyanın doğru görüntülenebilmesi ve okunabilmesi için, sahip olduğu kodlama biçiminin doğru olarak belirtilmesi gerekir. Ama okuyacağınız dosyaların hangi kodlama sistemine sahip olduğunu doğru tahmin etmeniz her zaman mümkün olmayabilir. Böyle durumlarda, programınızın çökmesini önlemek için çeşitli stratejiler belirlemeniz gerekir.
Bir önceki bölümde verdiğimiz örnekten de gördüğünüz gibi, eğer Python, açılmaya çalışılan dosyadaki karakterleri encoding parametresinde gösterilen kod çözücü ile çözemezse öntanımlı olarak bir hata mesajı üretip programdan çıkacaktır. Ancak sizin istediğiniz şey her zaman bu olmayabilir. Mesela dosyadaki karakterler doğru kodlanamasa bile programınızın çökmemesini tercih edebilirsiniz. İşte bunun için errors parametresinden yararlanacaksınız.
Bu parametreyi encoding() metodundan hatırlıyorsunuz. Bu parametre orada
nasıl kullanılıyorsa, open() fonksiyonunda da aynı şekilde kullanılır.
Dikkatlice bakın:
>>> f = open(dosya_adı, encoding='utf-8', errors='strict')
Bu zaten errors parametresinin öntanımlı değeridir. Dolayısıyla ‘strict’ değerini belirtmeseniz de öntanımlı olarak bu değeri belirtmişsiniz gibi davranılacaktır.
>>> f = open(dosya_adı, encoding='utf-8', errors='ignore')
Burada ise ‘ignore’ değerini kullanarak, Python’ın kodlanamayan karakterleri görmezden gelmesini sağlıyoruz.
>>> f = open(dosya_adı, encoding='utf-8', errors='replace')
‘replace’ değeri ise kodlanamayan karakterlerin yerine \ufffd karakterini
yerleştirecektir. Bu karakter işlev bakımından, encode() metodunu anlatırken
gördüğümüz ‘?’ işaretine benzer. Bu karaktere teknik olarak ‘UNICODE Değiştirme
Karakteri’ (UNICODE Replacement Character) adı verilir. Bazı yerlerde bu
karakteri elmas şeklinde siyah bir küp içine yerleştirilmiş soru işareti
şeklinde görebilirsiniz.
Peki encode() metodunu anlatırken errors parametresi ile birlikte
kullanabildiğimiz ‘xmlcharrefreplace’ değerini open() fonksiyonu ile
birlikte kullanabilir miyiz?
Hayır, open() fonksiyonu, errors parametresinde bu değerin kullanılmasına
izin vermez.
Konu ile ilgili Fonksiyonlar¶
Bu bölümde, karakter kodlama işlemleri esnasında işimize yarayacak bazı fonksiyonları ele alacağız.
repr()¶
İnceleyeceğimiz ilk fonksiyonun adı repr(). Esasında biz bu fonksiyonu
önceki derslerimizde de birkaç örnekte kullanmıştık. Belki o zaman bu
fonksiyonun ne işe yaradığını deneme-yanılma yoluyla anlamış olabilirsiniz. Eğer
henüz bu fonksiyonun görevini anlamadıysanız da mesele değil. Bu bölümde bu
fonksiyonu ve işlevini ayrıntılı bir şekilde anlatmaya çalışacağız.
Dilerseniz repr() fonksiyonunu anlatmaya bir örnek ile başlayalım.
Şimdi Python’ın etkileşimli kabuğunu açarak şu kodu yazın:
>>> "Python programlama dili"
Bu kodu yazıp ENTER düğmesine bastığınızda şöyle bir çıktı alacağınızı biliyorsunuz:
>>> 'Python programlama dili'
Dikkat ettiyseniz, yukarıdaki kodların çıktısında karakter dizisi tırnak
işaretleri içinde gösteriliyor. Eğer bu karakter dizisini print() fonksiyonu
içine yazarsanız o tırnak işaretleri kaybolacaktır:
>>> print("Python programlama dili")
Python programlama dili
Peki bu iki farklı çıktının sebebi ne?
Python programlama dilinde nesneler iki farklı şekilde temsil edilir:
Python’ın göreceği şekilde
Kullanıcının göreceği şekilde
Yukarıdaki ilk kullanım, yazdığımız kodu Python programlama dilinin nasıl
gördüğünü gösteriyor. İkinci kullanım ise aynı kodu bizim nasıl gördüğümüzü
gösteriyor. Zaten bu yüzden, etkileşimli kabukta print() fonksiyonu içinde
yazmadığımız karakter dizilerinin çıktılarını ekranda görebildiğimiz halde, aynı
karakter dizilerini bir dosyaya yazıp kaydettiğimizde ekranda çıktı olarak
görebilmek için bunları print() fonksiyonu içine yazmamız gerekiyor.
Bu söylediklerimiz biraz karmaşık gelmiş olabilir. İsterseniz ne anlatmaya çalıştığımızı daha açık bir örnek üzerinde gösterelim. Şimdi tekrar etkileşimli kabuğu açıp şu kodu çalıştıralım:
>>> "birinci satır\n"
Bu komut bize şu çıktıyı verdi:
'birinci satır\n'
Şimdi aynı kodu bir de şöyle yazalım:
>>> print("birinci satır\n")
birinci satır
Gördüğünüz gibi, ilk kodun çıktısında satır başı karakteri (\n) görünürken, ikinci kodun çıktısında bu karakter görünmüyor (ama işlevini yerine getiriyor. Yani satır başına geçilmesini sağlıyor).
İşte bunun sebebi, ilk kodun Python’ın bakış açısını yansıtırken, ikinci kodun bizim bakış açımızı yansıtmasıdır.
Peki bu bilgi bizim ne işimize yarar?
Şimdi şöyle bir örnek düşünün:
Diyelim ki elimizde şöyle bir değişken var:
>>> a = "elma "
Şimdi bu değişkeni ekrana çıktı olarak verelim:
>>> print(a)
elma
Gördüğünüz gibi, bu çıktıya bakarak, a değişkeninin tuttuğu karakter dizisinin son tarafında bir adet boşluk karakteri olduğunu anlayamıyoruz. Bu yüzden bu değişkeni şöyle bir program içinde kullanmaya çalıştığımızda neden bozuk bir çıktı elde ettiğimizi anlamak zor olabilir:
>>> print("{} kilo {} kaldı!".format(23, a))
23 kilo elma kaldı!
Gördüğünüz gibi, “elma” karakter dizisinin son tarafında bir boşluk olduğu için ‘elma’ ile ‘kaldı’ kelimeleri arasında gereksiz bir açıklık meydana geldi.
Bu boşluğu print() ile göremiyoruz, ama bu değişkeni print() olmadan
yazdırdığımızda o boşluk da görünür:
>>> a
'elma '
Bu sayede programınızdaki aksaklıkları giderme imkanı kazanmış olur, şu kodu yazarak gereksiz boşlukları atabilirsiniz:
>>> print("{} kilo {} kaldı!".format(23, a.strip()))
23 kilo elma kaldı!
Daha önce de dediğimiz gibi, başında print() olmayan ifadeler, bir dosyaya
yazılıp çalıştırıldığında çıktıda görünmez. O halde biz yukarıdaki özellikten
yazdığımız programlarda nasıl yararlanacağız? İşte burada yardımımıza repr()
adlı bir fonksiyon yetişecek. Bu fonksiyonu şöyle kullanıyoruz:
print(repr("karakter dizisi\n"))
Bu kodu bir dosyaya yazıp kaydettiğimizde şöyle bir çıktı alıyoruz:
'karakter dizisi\n'
Gördüğünüz gibi hem tırnak işaretleri, hem de satır başı karakteri çıktıda
görünüyor. Eğer repr() fonksiyonunu kullanmasaydık şöyle bir çıktı
alacaktık:
karakter dizisi
repr() fonksiyonu özellikle yazdığımız programlardaki hataları çözmeye
çalışırken çok işimize yarar. Çünkü print() fonksiyonu, kullanıcının gözüne
daha cazip görünecek bir çıktı üretebilmek için arkaplanda neler olup bittiğini
kullanıcıdan gizler. İşte arkaplanda neler döndüğünü, print() fonksiyonunun
bizden neleri gizlediğini görebilmek için bu repr() fonksiyonundan
yararlanabiliriz.
Not
repr() fonksiyonu ile ilgili gerçek hayattan bir örnek için
istihza.com/blog/windows-python-3-2de-bir-hata.html
(arşiv linki)adresindeki yazımızı okuyabilirsiniz.
Bütün bu açıklamalar bize şunu söylüyor: repr() fonksiyonu, bir karakter
dizisinin Python tarafından nasıl temsil edildiğini gösterir. Yukarıda biz bu
fonksiyonun nasıl kullanıldığına dair ayrıntıları verdik. Ancak bu fonksiyonun,
yine yukarıdaki işleviyle bağlantılı olmakla birlikte biraz daha farklı görünen
bir işlevi daha bulunur.
Hatırlarsanız, ilk derslerimizde r adlı bir kaçış dizisinden söz etmiştik. Bu kaçış dizisini şöyle kullanıyorduk:
print(r"\n")
Bildiğiniz gibi, \n kaçış dizisi bir alt satıra geçmemizi sağlıyor. İşte r adlı kaçış dizisi \n kaçış dizisinin bu işlevini baskılayarak, bizim \n kaçış dizisinin kendisini çıktı olarak verebilmemizi sağlıyor.
O halde bu noktada size şöyle bir soru sormama izin verin:
Acaba bir değişkene atanmış kaçış dizilerinin işlevini nasıl baskılayabiliriz? Yani mesela elimizde şöyle bir değişken bulunuyor olsun:
yeni_satır = "\n"
Biz bu değişkenin değerini nasıl ekrana yazdıracağız?
Eğer bunu doğrudan print() fonksiyonuna gönderirsek ne olacağını
biliyorsunuz: Yeni satır karakteri işlevini yerine getirecek ve biz de yeni
satır karakterinin kendisini değil, yaptığı işin sonucunu (yani satır başına
geçildiğini) göreceğiz.
İşte bu tür durumlar için de repr() fonksiyonundan yararlanabilirsiniz:
print(repr('\n'))
Böylece satır başı karakterinin işlevi baskılanacak ve biz çıktıda bu karakterin kendisini göreceğiz.
Hatırlarsanız ASCII konusunu anlatırken şöyle bir örnek vermiştik:
for i in range(128):
if i % 4 == 0:
print("\n")
print("{:<3}{:>8}\t".format(i, repr(chr(i))), sep="", end="")
İşte burada, repr() fonksiyonunun yukarıda sözünü ettiğimiz işlevinden
yararlanıyoruz. Eğer bu kodlarda repr() fonksiyonunu kullanmazsak, ASCII
tablosunu oluşturan karakterler arasındaki \n, \a, \t gibi kaçış
dizileri ekranda görünmeyecek, bunun yerine bu kaçış dizileri doğrudan
işlevlerini yerine getirecek, bu da bizim istediğimiz ASCII tablosunu üretmemize
engel olacaktır.
ascii()¶
ascii() fonksiyonu biraz önce öğrendiğimiz repr() fonksiyonuna çok
benzer. Örneğin:
>>> repr("asds")
"'asds'"
>>> ascii("asds")
"'asds'"
Bu iki fonksiyon, ASCII tablosunda yer almayan karakterlere karşı tutumları yönünden birbirlerinden ayrılır. Örneğin:
>>> repr("İ")
"'İ'"
>>> ascii("İ")
"'\\u0130'"
Gördüğünüz gibi, repr() fonksiyonu ASCII tablosunda yer almayan
karakterleri de göründükleri gibi temsil ediyor. ascii() fonksiyonu ise bu
karakterlerin UNICODE kod konumlarını (code points) gösteriyor.
Bir örnek daha verelim:
>>> repr("€")
"'€'"
>>> ascii("€")
"'\\u20ac'"
ascii() fonksiyonunun UNICODE kod konumlarını gösterme özelliğinin bir
benzerini daha önce öğrendiğimiz encode() metodu yardımıyla da elde
edebilirsiniz:
>>> "€".encode("unicode_escape")
b'\\u20ac'
Ancak ascii() fonksiyonunun str tipinde, encode() metodunun ise
bytes tipinde bir çıktı verdiğine dikkat edin.
ord()¶
Bu fonksiyon, bir karakterin sayı karşılığını verir:
>>> ord("\n")
10
>>> ord("€")
8364
chr()¶
Bu fonksiyon, bir sayının karakter karşılığını verir:
>>> chr(10)
'\n'
>>> chr(8364)
'€'
Önemli Not
Sorularınızı yorumlarda dile getirmek yerine Yazbel Forumunda sorarsanız çok daha hızlı cevap alabilirsiniz.Belgelerdeki bir hata veya eksiği dile getirecekseniz lütfen yorumları kullanmak yerine Github'da bir konu (issue) açın.
Eğer yazdığınız yorum içinde kod kullanacaksanız kodlarınızı <pre><code> etiketleri içine alın. Örneğin:
<pre><code class="python">
print("Merhaba Dünya!")
</code></pre>
